python
43 lines · 1 tab
Priya Sharma
Jan 2026
1 tab
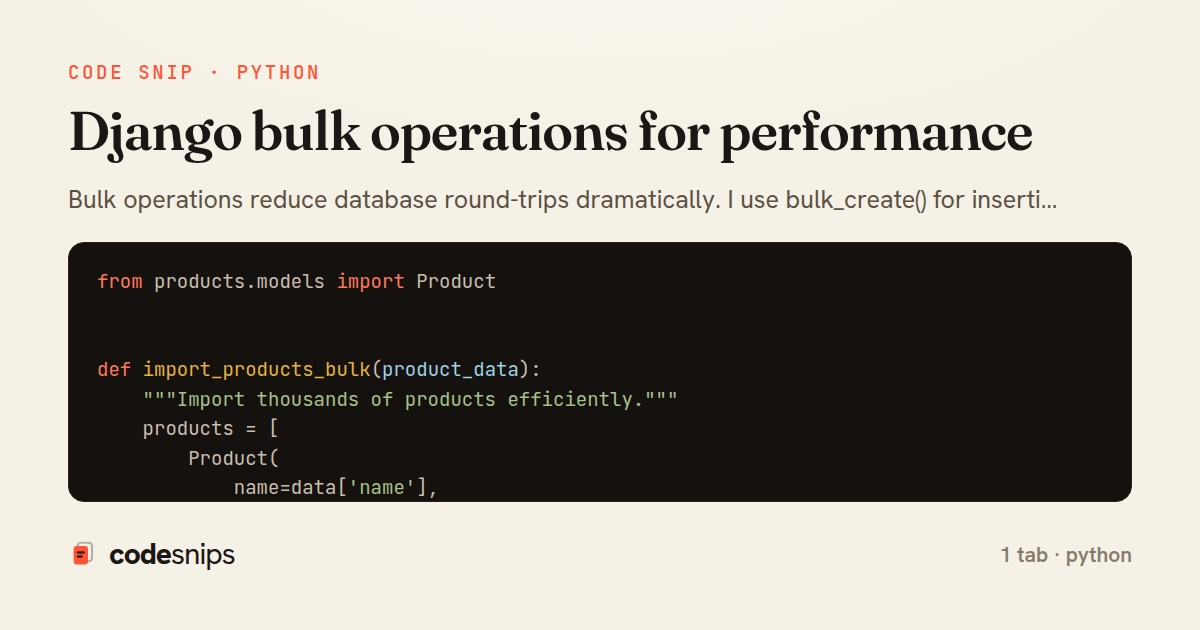
from products.models import Product
def import_products_bulk(product_data):
"""Import thousands of products efficiently."""
products = [
Product(
name=data['name'],
price=data['price'],
sku=data['sku']
)
for data in product_data
]
# Insert all at once
Product.objects.bulk_create(products, batch_size=1000)
def update_prices_bulk(price_updates):
"""Update many products' prices."""
products = []
for product_id, new_price in price_updates.items():
product = Product(id=product_id, price=new_price)
products.append(product)
# Update all at once
Product.objects.bulk_update(products, ['price'], batch_size=500)
def discount_category(category_id, discount_percent):
"""Apply discount to all products in category."""
from django.db.models import F
Product.objects.filter(category_id=category_id).update(
price=F('price') * (1 - discount_percent / 100)
)
def process_large_queryset():
"""Process millions of records without memory issues."""
for product in Product.objects.iterator(chunk_size=2000):
# Process one at a time
process_product(product)
1 file · python
Explain with highlit
Bulk operations reduce database round-trips dramatically. I use bulk_create() for inserting many objects at once, bulk_update() for updates, and update() for queryset-level updates. These bypass save() methods and signals for speed. For large datasets, I batch operations with batch_size parameter. I use iterator() to stream large querysets without loading all into memory. The delete() method on querysets deletes in bulk. These patterns are essential for data imports, exports, and batch processing tasks.
Related snips
python
import os
import stat
for root, _dirs, files in os.walk('/etc'):
for name in files:
path = os.path.join(root, name)Python security audit script for exposed risky filesystem state
python
auditing
host-security
by Kai Nakamura
1 tab
python
class Product(models.Model):
name = models.CharField(max_length=200)
slug = models.SlugField(blank=True)
price = models.DecimalField(max_digits=10, decimal_places=2)
cost = models.DecimalField(max_digits=10, decimal_places=2)
margin = models.DecimalField(max_digits=5, decimal_places=2, blank=True)Django model signals vs overriding save
django
python
models
by Priya Sharma
2 tabs
ruby
require "csv"
class PeopleCsvStream
include Enumerable
HEADERS = %w[id full_name email signed_up_at plan].freezeResilient CSV Export as a Streamed Response
rails
performance
streaming
by codesnips
3 tabs
ruby
Rails.application.configure do
config.after_initialize do
Bullet.enable = true
Bullet.alert = false
Bullet.bullet_logger = true
Bullet.console = trueN+1 query detection with Bullet gem
rails
performance
activerecord
by Alex Kumar
2 tabs
python
from django.urls import path
from . import views
app_name = 'blog'
urlpatterns = [Django URL namespacing and reverse lookups
django
python
urls
by Priya Sharma
3 tabs
ruby
# Vulnerable: user input is concatenated directly into SQL.
email = params[:email]
password = params[:password]
sql = "SELECT * FROM users WHERE email = '#{email}' AND password_hash = '#{password}'"
user = ActiveRecord::Base.connection.execute(sql).firstSQL injection prevention with unsafe and safe query patterns
sql-injection
owasp
database
by Kai Nakamura
3 tabs
Share this code
Here's the card — post it anywhere.