python
11 lines · 1 tab
Dr. Elena Vasquez
Apr 2026
1 tab
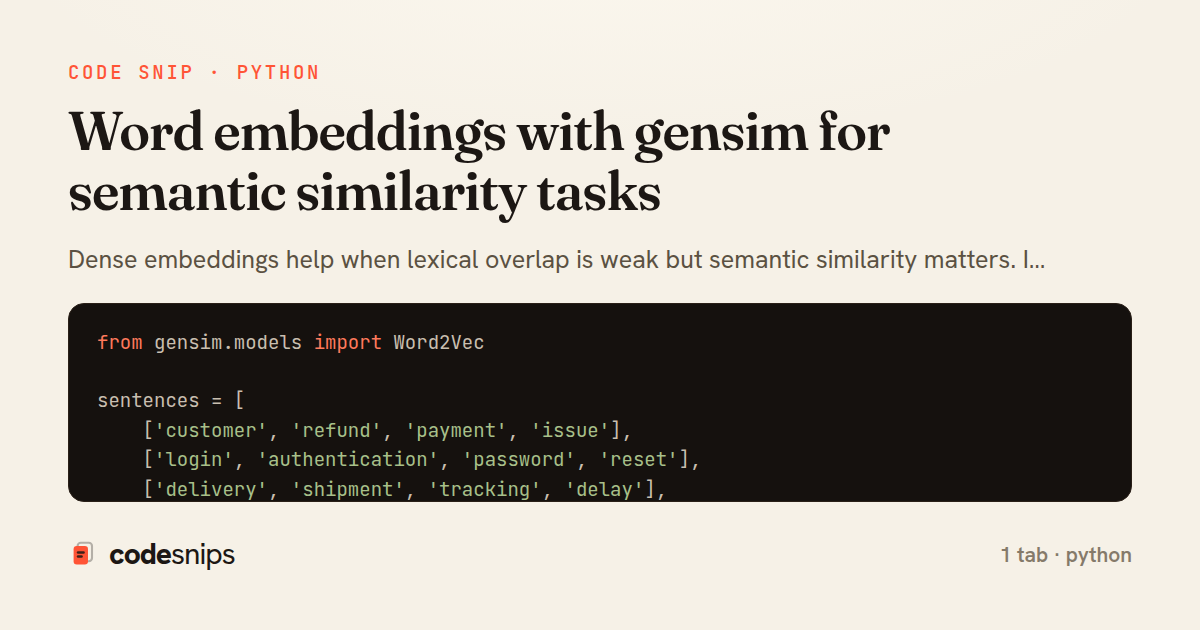
from gensim.models import Word2Vec
sentences = [
['customer', 'refund', 'payment', 'issue'],
['login', 'authentication', 'password', 'reset'],
['delivery', 'shipment', 'tracking', 'delay'],
['refund', 'chargeback', 'billing', 'payment'],
]
model = Word2Vec(sentences=sentences, vector_size=100, window=5, min_count=1, workers=2, sg=1)
print(model.wv.most_similar('refund', topn=3))
1 file · python
Explain with highlit
Dense embeddings help when lexical overlap is weak but semantic similarity matters. I use them for retrieval prototypes, clustering, and feature enrichment when transformer infrastructure is overkill. The main discipline is keeping training data clean and checking nearest neighbors for obvious failure modes.
Share this code
Here's the card — post it anywhere.